BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

By A Mystery Man Writer

arxiv-sanity

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

arxiv-sanity

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

miro.medium.com/v2/resize:fit:1400/1*tIkCREGvFWTIK

Running Fast Transformers on CPUs: Intel Approach Achieves Significant Speed Ups and SOTA Performance
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Speeding up BERT model inference through Quantization with the Intel Neural Compressor

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models
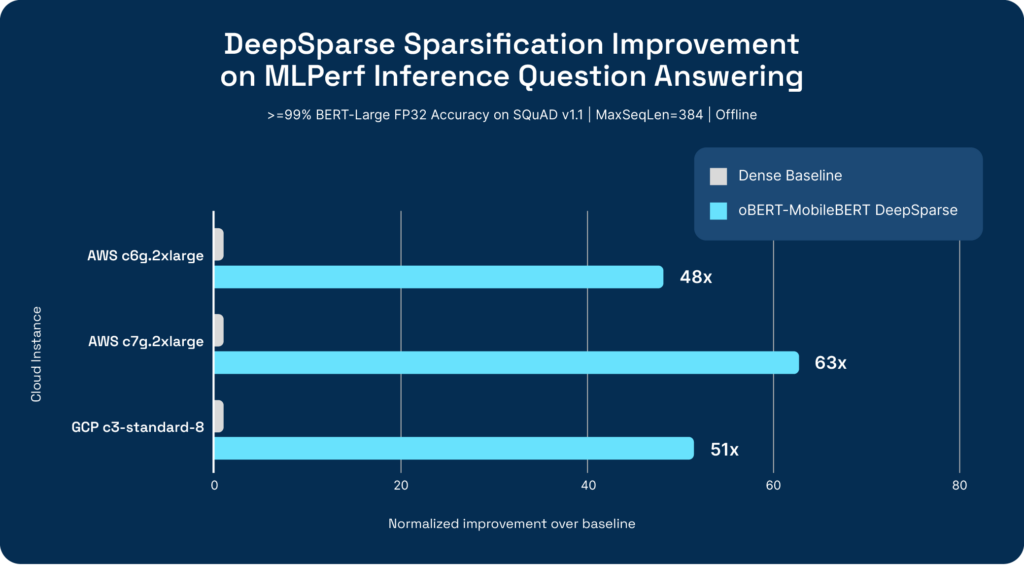
Latest MLPerf™ Inference v3.1 Results Show 50X Faster AI Inference for x86 and ARM from Neural Magic - Neural Magic
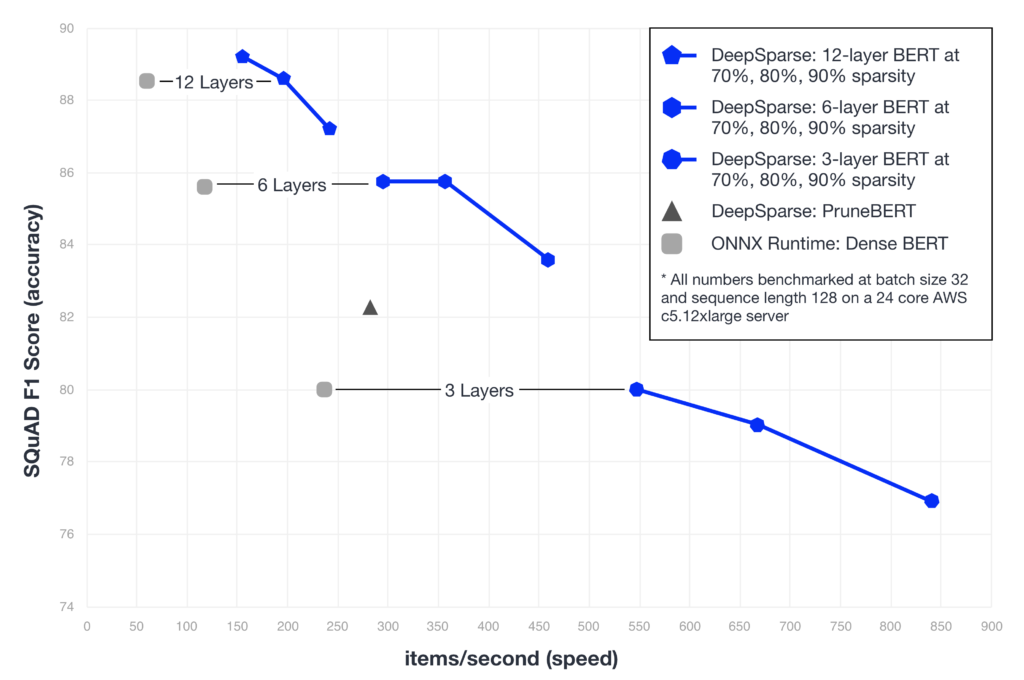
Pruning Hugging Face BERT with Compound Sparsification - Neural Magic

arxiv-sanity
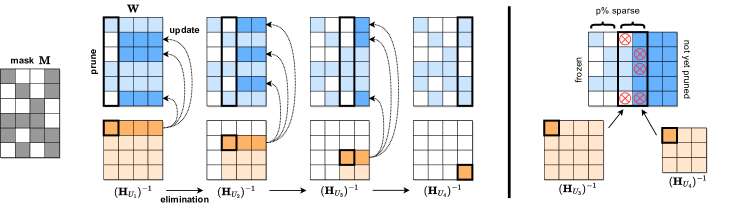
2301.00774] Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning
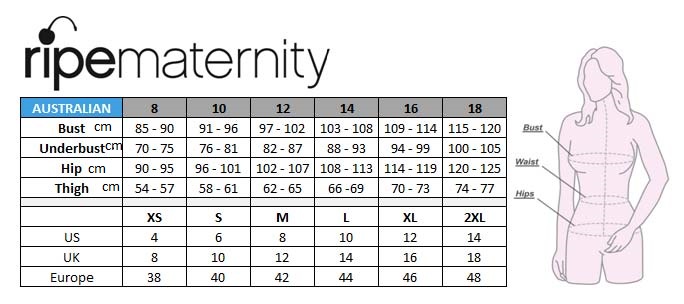
- Maternity Size Chart Motherhood Closet - Maternity Consignment
- PharmaSystems Weekly Pill Planner Box 1x per day (X-Large)

- Womens Medical Scrub Set GT 4FLEX Vneck Top and Pant-Caribbean-X-Large
- ALLEGRACE Women Pants Plus Size Causal Dressy High Waist Skinny Capris for Work Brown & Black Plaid 14W at Women's Clothing store

- When you create the most perfect personalised hand luggage bag





