Retrieval Augmented Generation (RAG) Inference Engines with LangChain on CPUs, by Eduardo Alvarez

By A Mystery Man Writer

Eduardo Alvarez – Medium

Improving LLM Inference Speeds on CPUs with Model Quantization, by Eduardo Alvarez, Feb, 2024
Retrieval Augmented Generation (RAG) Inference Engines with LangChain on CPUs

Eduardo Alvarez on LinkedIn: Improving Human-AI Interactions with More Accessible Deep Learning

Eduardo Alvarez on LinkedIn: 21st Century Paleontology with Machine Learning

Learn oneAPI with our GitHub repository., Intel Software posted on the topic
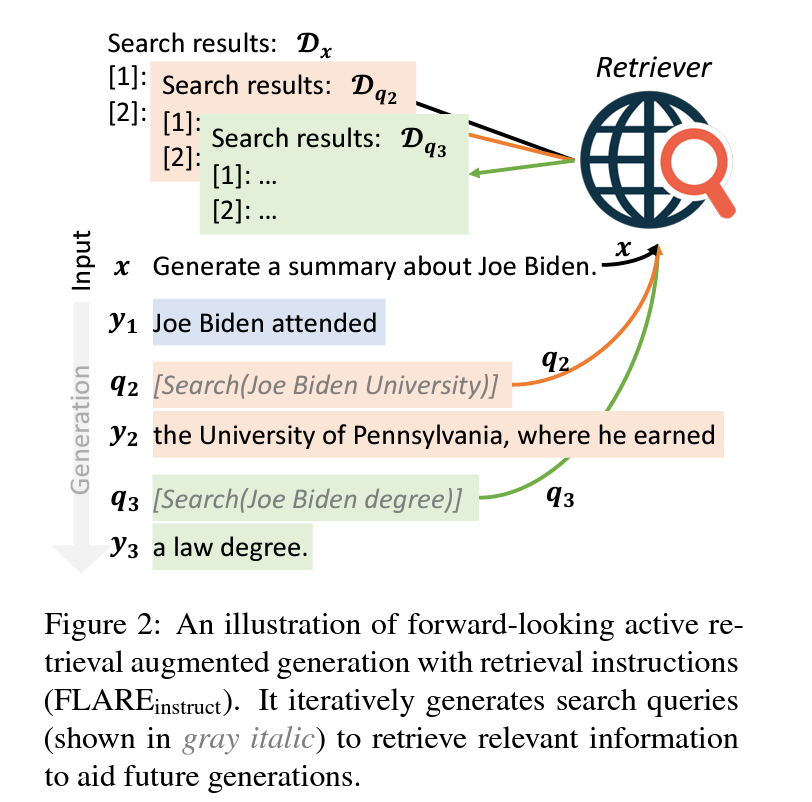
Harnessing Retrieval Augmented Generation With Langchain, by Amogh Agastya

List: LangChain, Curated by kubwa.co.kr

Livestream: Retrieval Augmented Generation (RAG) with LangChain and KDB.AI

List: RAG, Curated by openeye0

Fine-Tune Falcon 7-Billion on Xeon CPUs with Hugging Face and oneAPI, by Eduardo Alvarez

Information Retrieval For Retrieval Augmented Generation
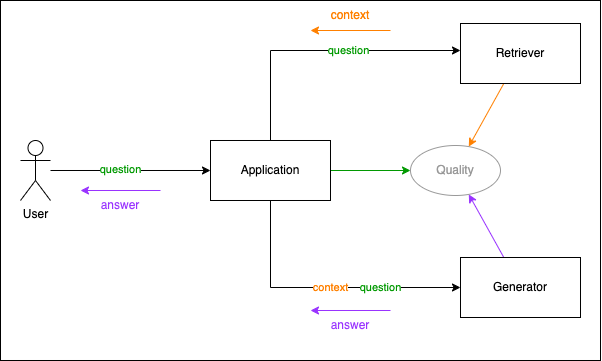
Launching RAG4j/p — Learning to program a Retrieval Augmented Generation system, by Jettro Coenradie





- Star Wars: The Clone Wars™ - Darth Vader™ Milestones Statue

- These gorgeous cotton blend tights with an all over pointelle knit design provide comfort and warmth and the lacey effect of the design will compliment any outfit – Minihaha

- BABY GIRLS BOW TIGHTS WHITE PINK FANCY PATTERNED PARTY OCCASION KIDS TIGHTS BOWS

- ULTRACOR Women's Clothing On Sale Up To 90% Off Retail

- Nike Breathe Elastika Dry Women's Running Training Gym Strappy
